
MPI4DL Performance
Machine Specifications
| CPU Model | CPU Core Info | Memory | IB Card | OS | GPU |
| AMD EPYC 7713 | 2x64 @ 2.3Ghz | 263 GB | Mellonox HDR (200 Gbps) | Rocky Linux 8.5 | NVIDIA A100-PCIE-40GB(2/Node) |
AmeobaNet f214
| Image Size |
1024 * 1024 |
2048 * 2048 |
||
| Batch-size |
1 |
2 |
1 |
2 |
|
Layer Parallelism (Images/Sec) |
2.68 |
3.37 |
0.97 |
1.22 |
|
Spatial Parallelism (Images/Sec) |
2.78 |
5.02 |
2.21 |
2.96 |
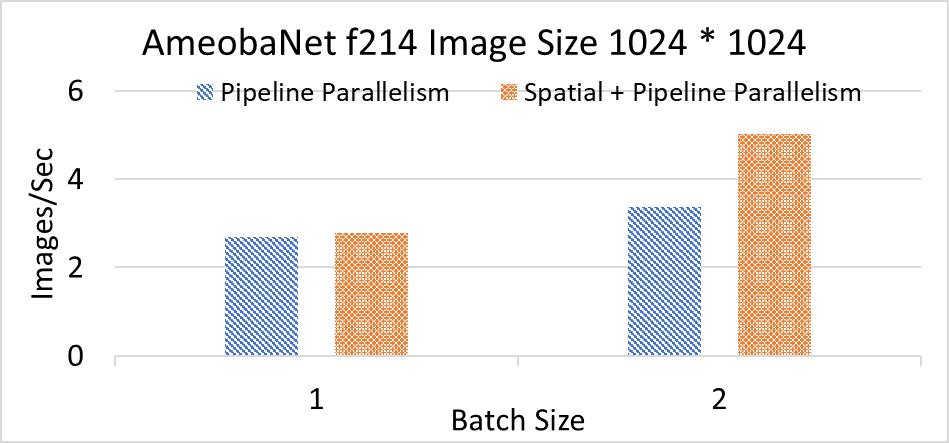
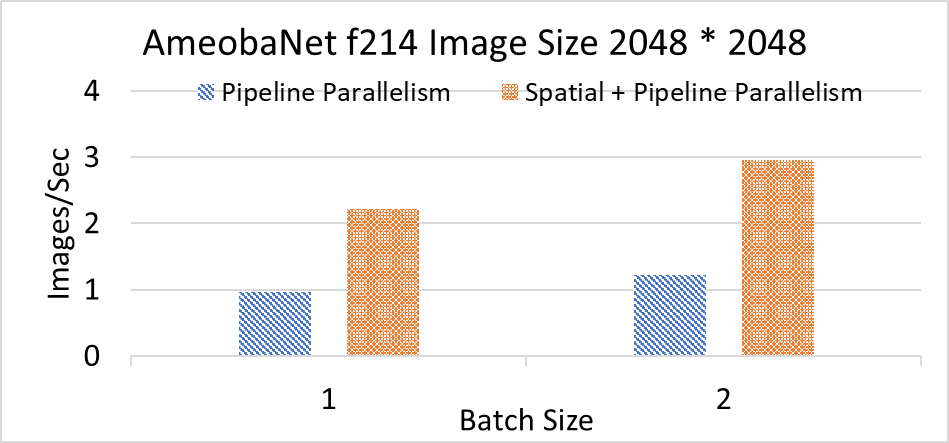
Above performance evaluation compares the throughput of Pipeline Parallelism and Pipeline + Spatial Parallelism techniques. The evaluation was conducted using a dataset provided by PyTorch and was performed on the OSU MRI cluster.
Performance comparison of Spatial and Bidirectional Parallelism for Ameobanet f214
| Batch-size |
2 |
4 |
|
Spatial Parallelism (Images/ Sec) |
0.88 |
0.97 |
|
Spatial + Bidirectional Parallelism (Images/ Sec) |
1.38 |
2.45 |
Performance comparison of Spatial and Bidirectional Parallelism for ResNet
| Batch-size |
2 |
4 |
|
Spatial Parallelism (Images/ Sec) |
0.65 |
0.64 |
|
Spatial + Bidirectional Parallelism (Images/ Sec) |
0.82 |
1.29 |
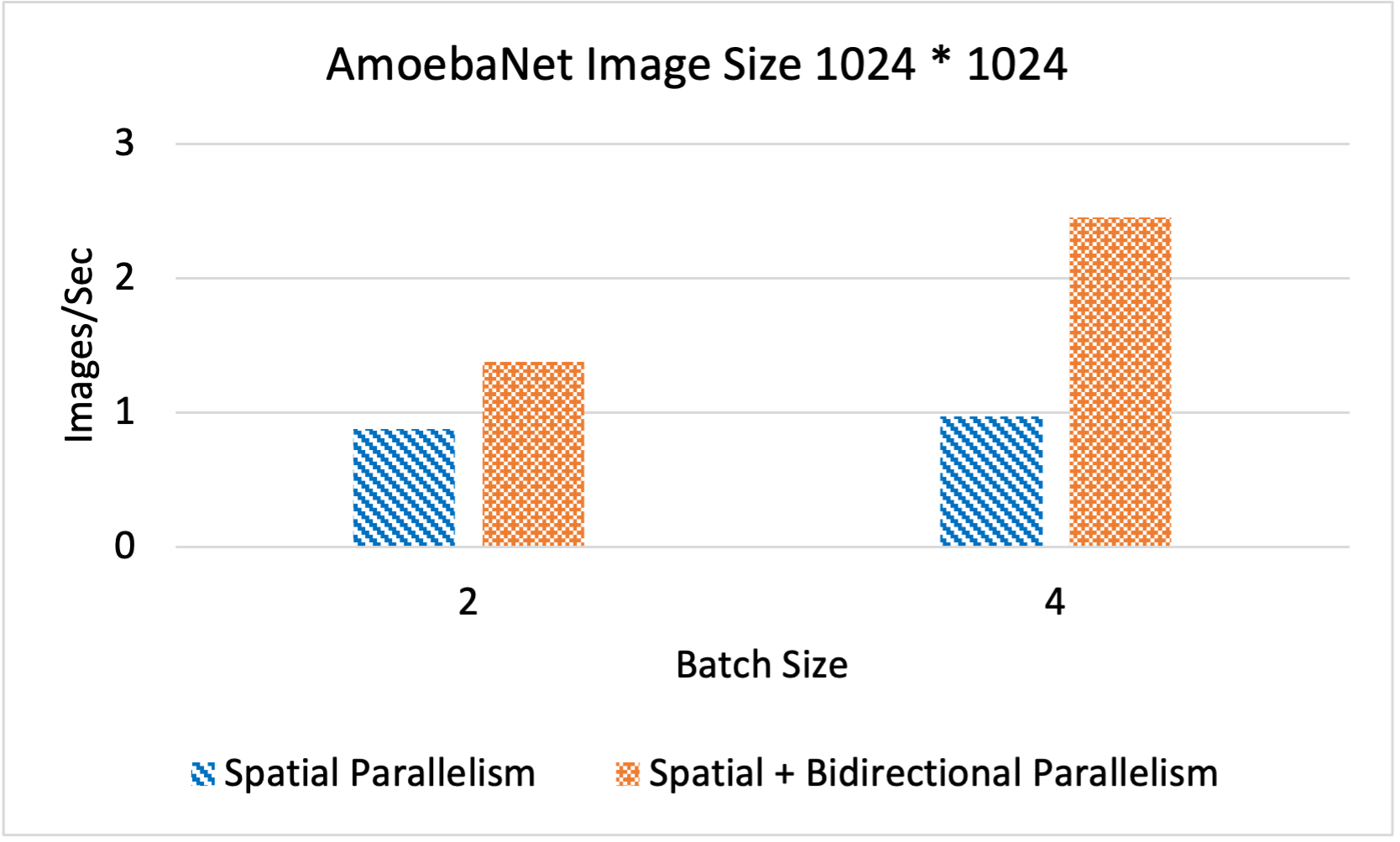
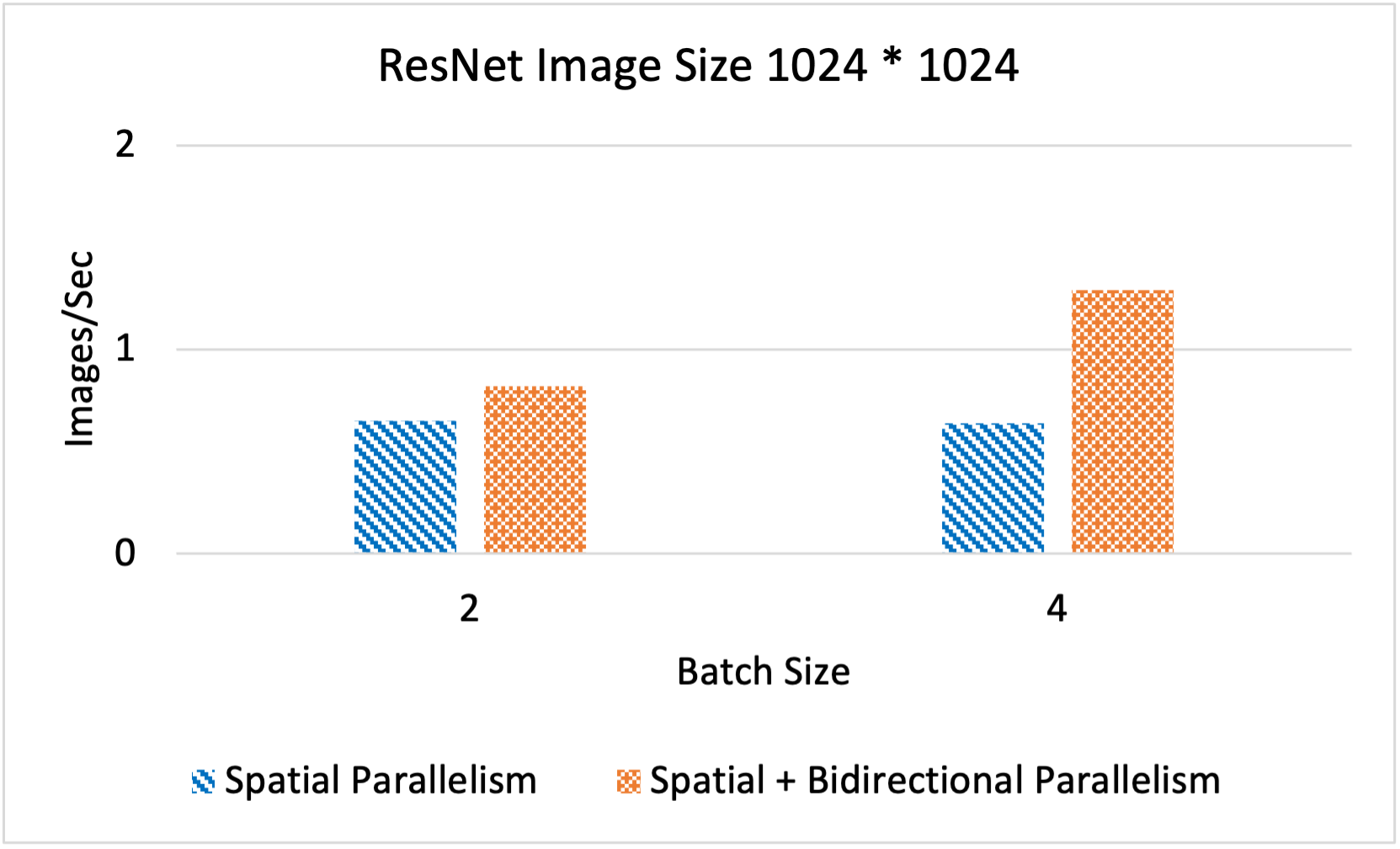
Above figures compare the performance of Spatial Parallelism and Spatial + Bidirectional Parallelism techniques with the following configurations: 5 model splits,4 spatial parts, and 2 model replicas for Bidirectional Parallelism. The evaluation was conducted using a dataset provided by PyTorch and was performed on the OSU MRI cluster.

