
RDMA-TensorFlow Performance
Machine Specifications
| CPU Model | CPU Core Info | Memory | IB Card | OS | OFED | GPU | CUDA |
|---|---|---|---|---|---|---|---|
| Intel E5-2680i v4 | 2x14 @ 2.4Ghz | 512GB | Mellanox EDR (100 Gbps) | CentOS 7.2 | MOFED 4.2-1.2.0 | NVIDIA Tesla K80 | CUDA 8.0/ CUDNN 5.0 |
For performance evaluation, we use TensorFlow CNN benchmark. This benchmark generates synthetic image data and measures the performance by the total number of images processed per second (higher is better). RDMA-TensorFlow uses AR-gRPC channel for the distributed training, while the default TensorFlow uses default gRPC channel over IPoIB. All the worker nodes use GPU, while the Parameter Server uses CPU. The graphs shows the batch size per GPU. The total batch size can be computed as (batch size per GPU * total number of GPUs).
Inception4 performance on 4 Nodes
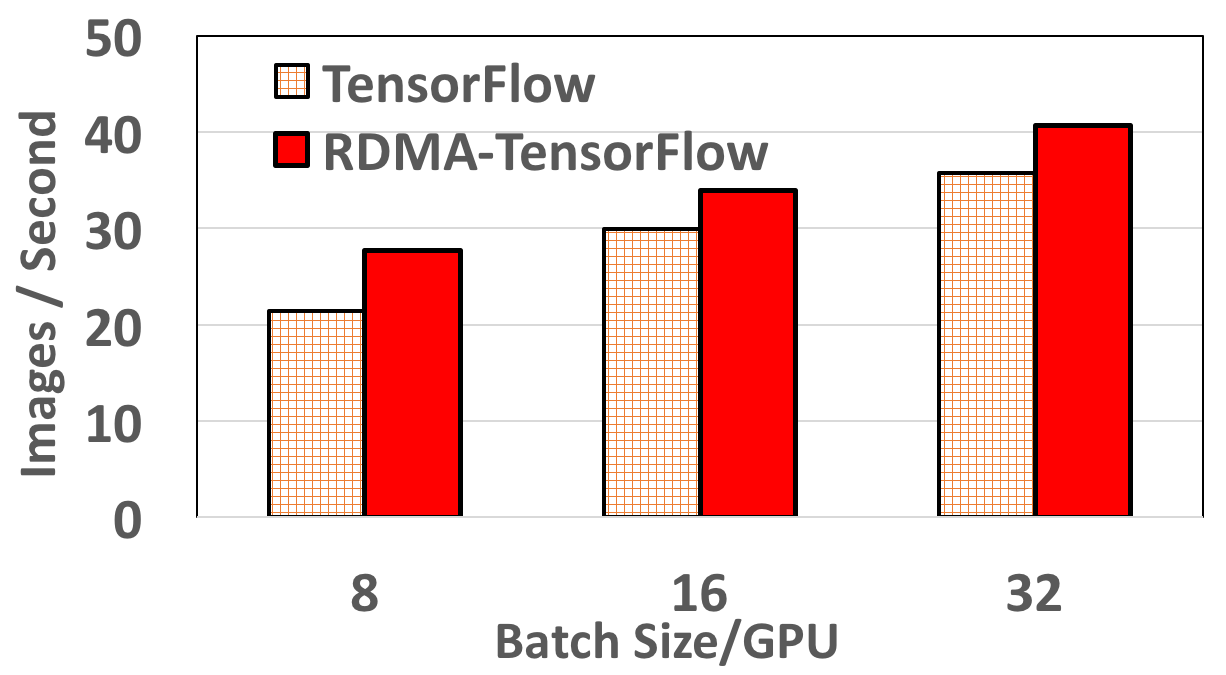
Inception4 performance on 8 Nodes
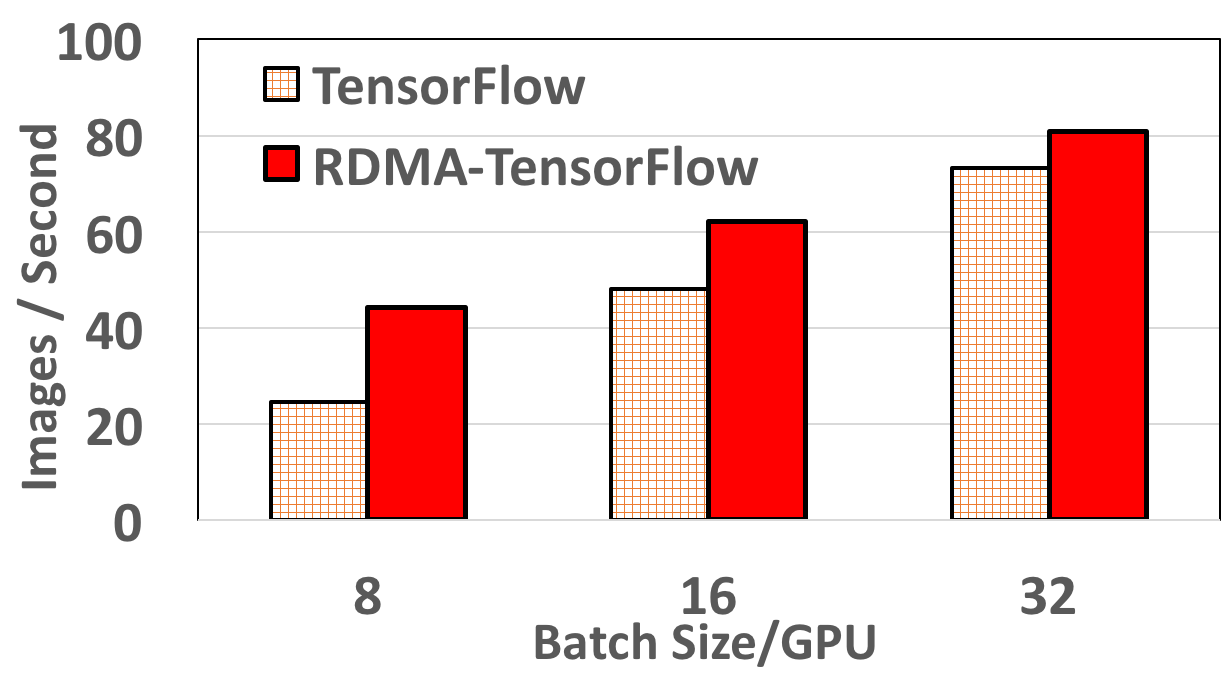
Inception4 performance on 12 Nodes
RDMA-TensorFlow improves DL training performance by a maximum of 29%, 80%, and 144% compared to default TensorFlow. For example, in 12 Nodes RDMA-TensorFlow improves performance of DL training by 80% (93 vs 51 images) for batch size 16/GPU (total 176) on 12 nodes.
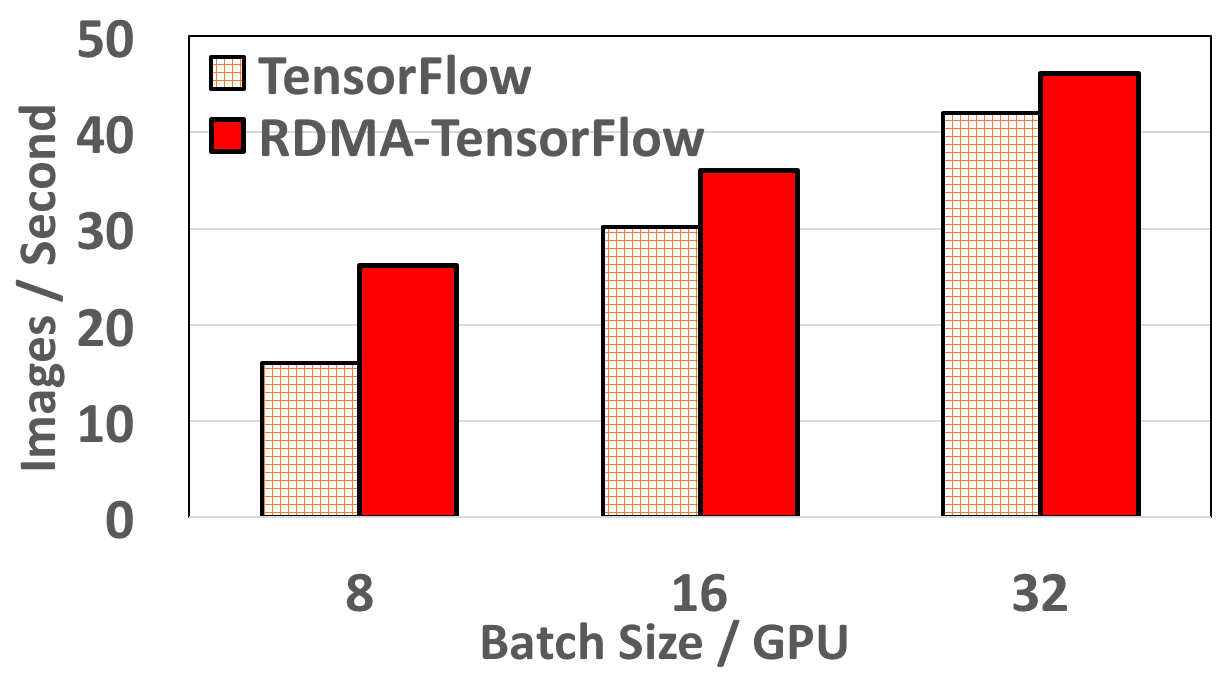
Resnet152 performance on 4 Nodes
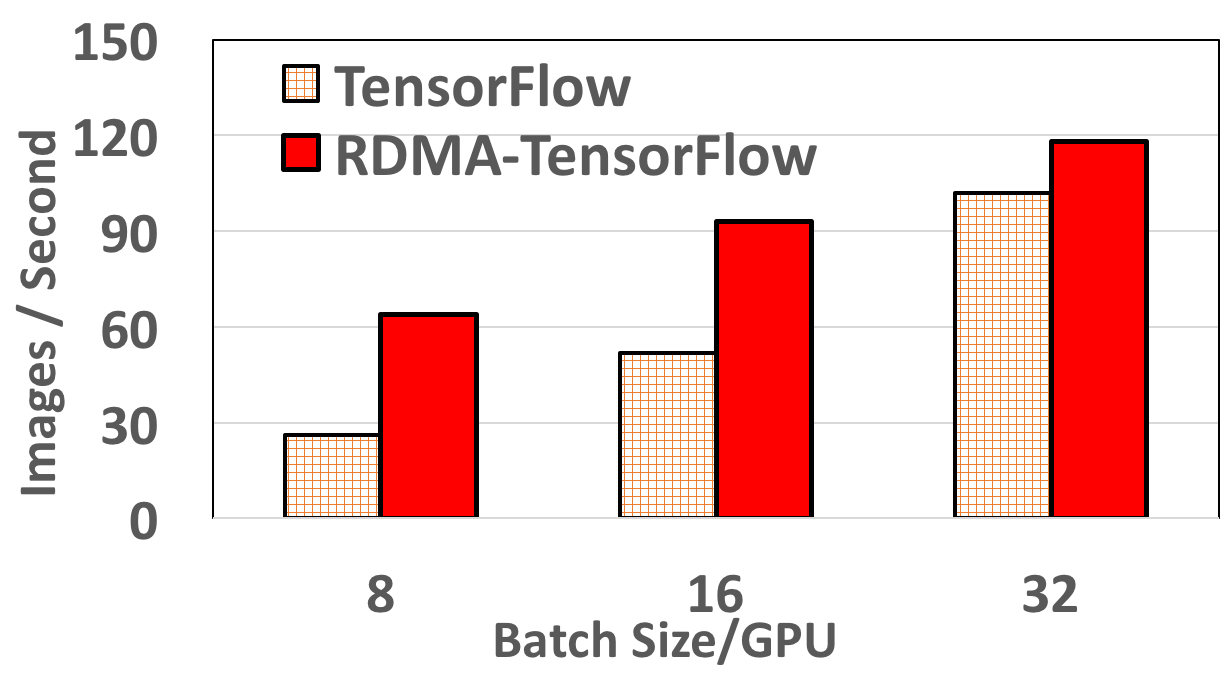
Resnet152 performance on 8 Nodes
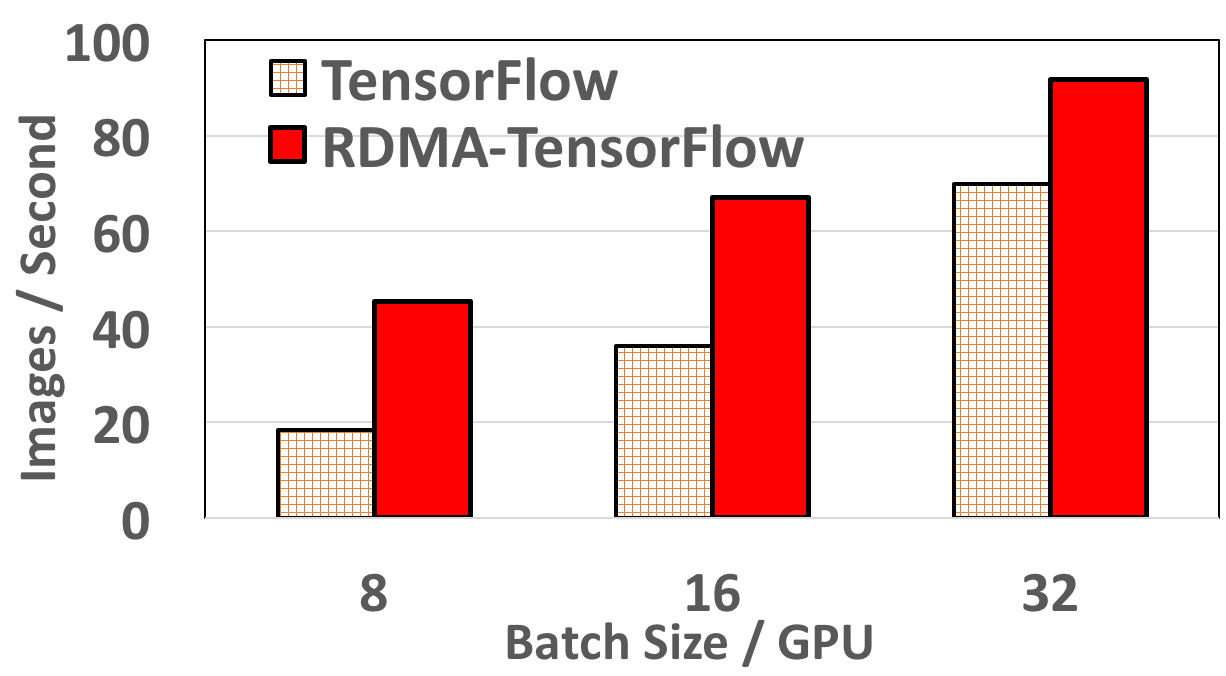
Resnet152 performance on 12 Nodes
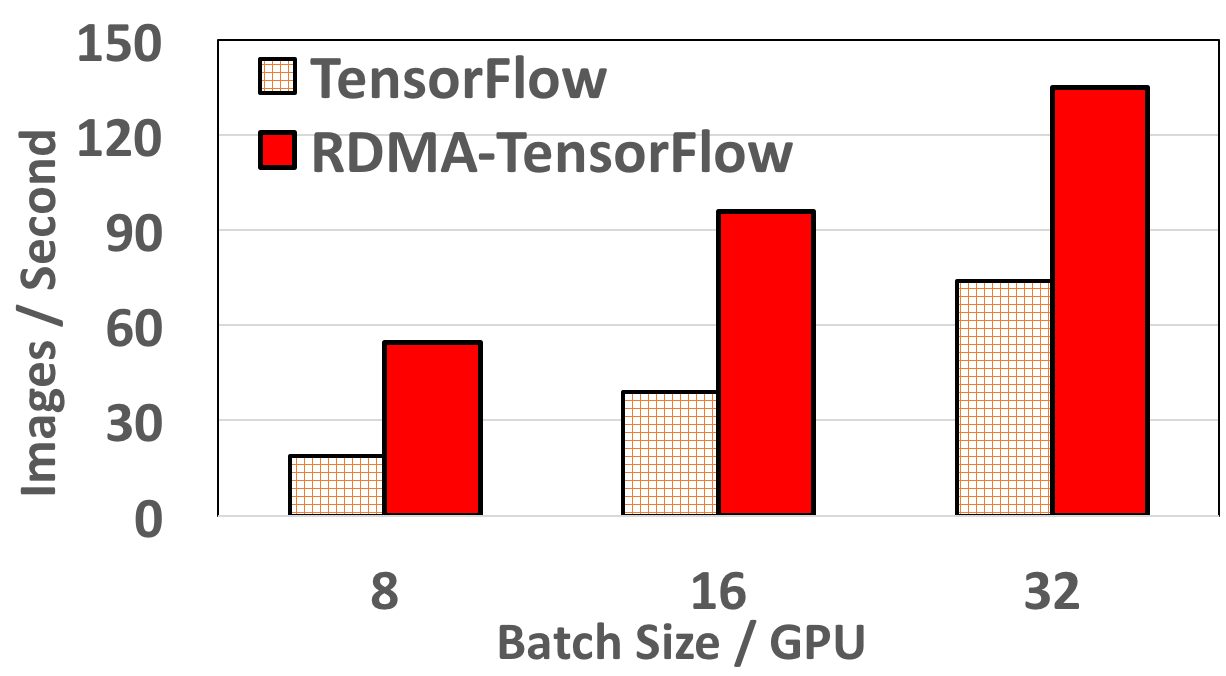
RDMA-TensorFlow accelerates performance by 62% (batch size 8/GPU) more compared to default TensorFlow for 4 Nodes. Also, for 8 Nodes, RDMA-TensorFlow improves Resnet152 performance by 32% (batch size 32/GPU) to 147% (batch size 8/GPU). For 12 nodes, RDMA-TensorFlow incurs a maximum speedup of 3x (55 vs 18 images) compared to default TensorFlow. Even for higher batch size (12 nodes) of 32/GPU (total 352) RDMA-TensorFlow improves TensorFlow performance by 82%.
GoogleNet and AlexNet performance on 4 Nodes
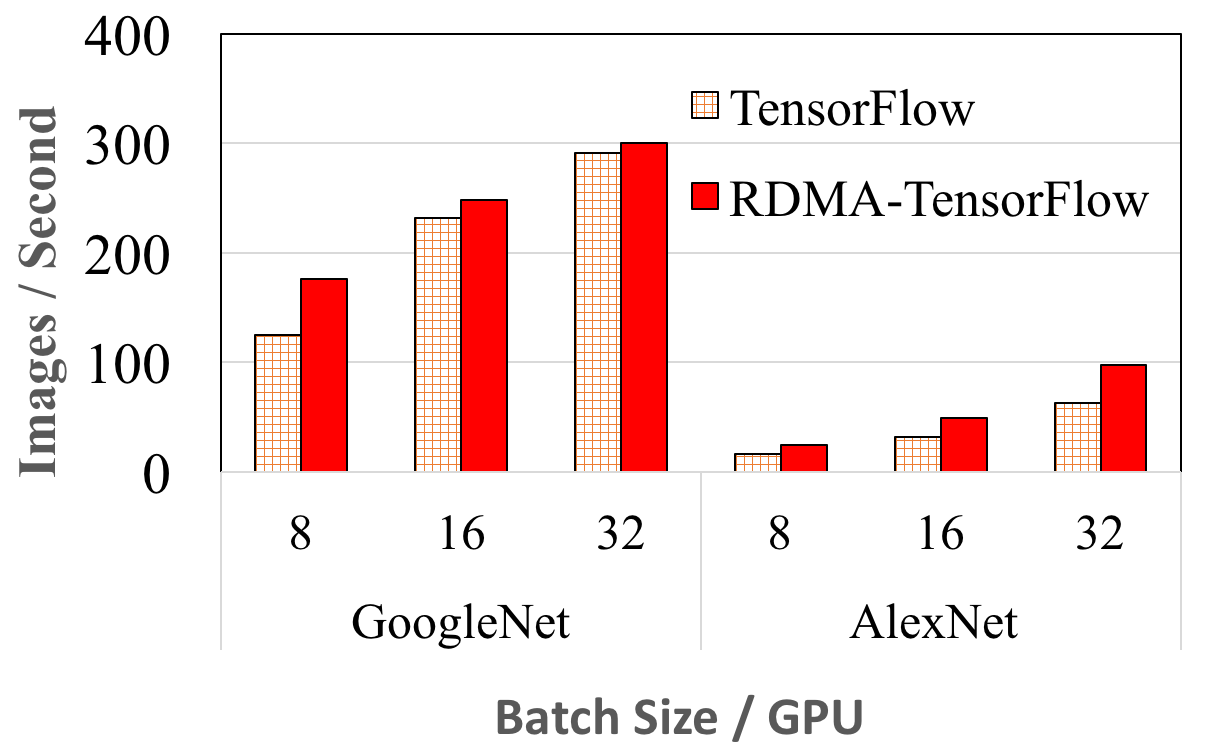
GoogleNet and AlexNet performance on 8 Nodes
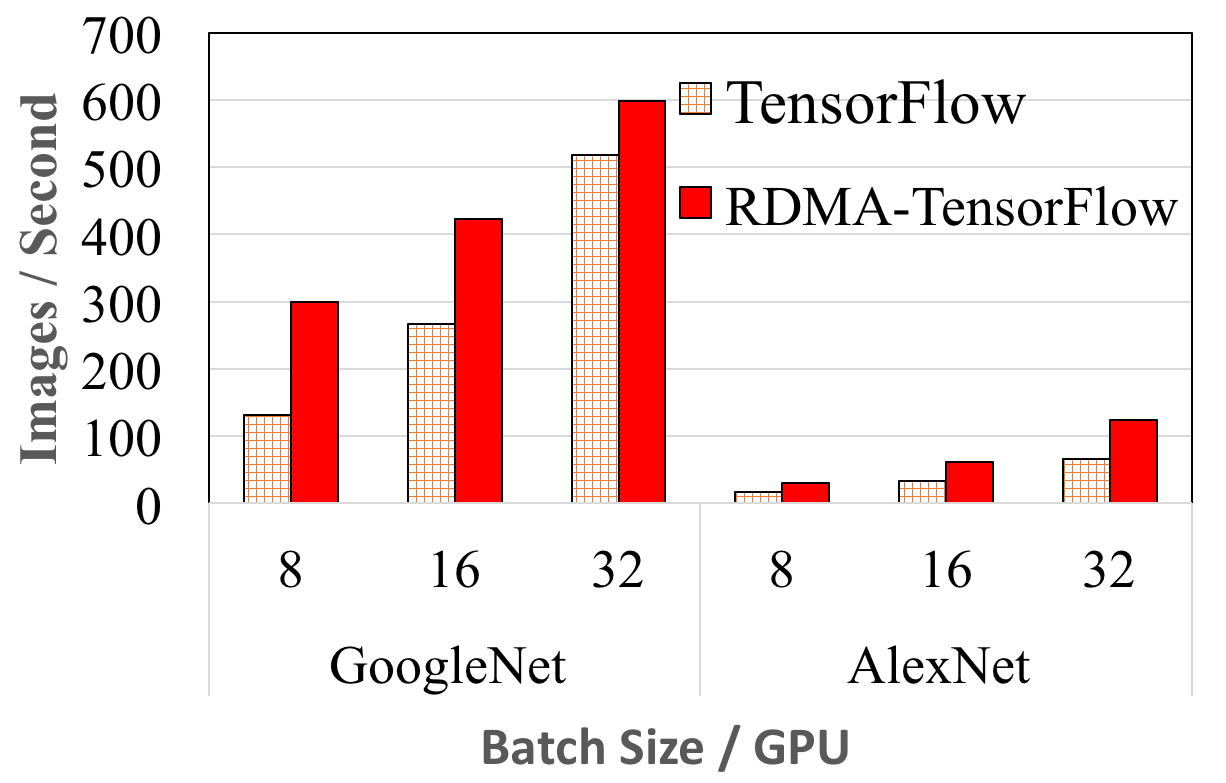
The above figures show the training performance comparison for GoogleNet and AlexNet among RDMA-TensorFlow and default TensorFlow on 4 and 8 nodes, respectively. GoogleNet has only 5 Million parameters, whereas AlexNet has about 60 Million parameters. The results shows that with increasing number of nodes RDMA-TensorFlow scales better. For example, for 4 nodes, RDMA-TensorFlow has almost identical performance to default TensorFlow for 16 and 32 batch size per GPU. However, as we go to 8 nodes the performance improvement over default TensorFlow become apparent. We have the same observation for AlexNet as well. Moreover, as shown for 8 nodes, RDMA-TensorFlow process a maximum of 128% (batch size 8/GPU) more images than default TensorFlow for GoogleNet. Although, for large batch size (32/GPU, total 224) the improvement is about 15% (597 vs 517). This is expected as higher batch size and less parameters in GoogleNet results in less network intensive gradient updates. In comparison, for the same batch size (32/GPU) RDMA-TensorFlow shows 89% (124 vs 65) performance improvement for Alexnet compared to default TensorFlow (8 Nodes).
These numbers were taken on OSU RI2 cluster.

